This note describes the history of expandfile, a simple Unix command line program for expanding templates.
History
expandfile is a command line program that reads input files and writes output on standard output.
(It runs on MacOS, Linux, or Windows. It is an open source Perl program, MIT license, ![]() available on GitHub.)
available on GitHub.)
I wrote expandfile in 2002 to replace a collection of ad hoc Perl programs that I had been using to maintain the multicians.org website since 1995. Since 2002, I've added features to expandfile occasionally.
I wanted to make it easy to change my site, to ensure website performance remained acceptable, and to prevent or catch mistakes. I wanted a tool that would work for many different kinds of web sites.
Web pages written in the HTML language are sent over the Internet from a web server program on a server host to a web browser program running on a user device. I chose to create static HTML pages and have the web server serve them without any change at request time. Because multicians.org had mirror sites where I could not modify the web server configuration or execute code on the server, I could not dynamically generate web pages, even if I wanted to. Furthermore, at the time, people implementing web sites by generating pages dynamically from databases, like bulletin board systems, were encountering web server performance and security problems.
My ISP's web servers supported a "server side include" feature, which let users insert the contents of auxiliary files when serving a web page. When I tried to separate my pages into content and boilerplate, I found that I wanted to have the boilerplate be slightly different for each page, so I sought a method where the boilerplate content could be tailored depending on the page. The organization I chose was:
- Each "object" HTML web page was expanded from a "source" file.
- Source files were stored in the file system on my personal computer.
- There was one source file for each page, plus additional boilerplate source files included by multiple pages.
- Source and boilerplate files were compiled into HTML "object" files on my computer when necessary.
- Object files were stored in the file system on my computer and copied verbatim to the server computers when changed.
- Object files in server computers' file systems were HTML, ready to serve.
- The server computers' web servers could respond to requests with maximum efficiency, without expanding anything.
The idea of a simple macro expander dates back to ![]() Christopher Strachey's GPM macro expander,
which I had experimented with in the mid 60s on CTSS at MIT Project MAC.
Later, I used several computer languages that used pre-processors to add features to their languages, such as ALM, PL/I, and C:
they provided features such as including other input files and macro expansion.
Christopher Strachey's GPM macro expander,
which I had experimented with in the mid 60s on CTSS at MIT Project MAC.
Later, I used several computer languages that used pre-processors to add features to their languages, such as ALM, PL/I, and C:
they provided features such as including other input files and macro expansion.
Jerry Saltzer's ![]() RUNOFF is an archetype text-transformation program;
I had used it in the 60s on CTSS.
RUNOFF's input is either text to be copied to the output,
or commands that change the state of execution and affect how later processing works.
Later implementations of RUNOFF-like languages in Multics and elsewhere included the ideas of
semantic markup, macro expansion, and multi-pass processing.
RUNOFF is an archetype text-transformation program;
I had used it in the 60s on CTSS.
RUNOFF's input is either text to be copied to the output,
or commands that change the state of execution and affect how later processing works.
Later implementations of RUNOFF-like languages in Multics and elsewhere included the ideas of
semantic markup, macro expansion, and multi-pass processing.
I decided to write my own source text expansion tool that did not parse the underlying input language, similar to GPM: it would just transform text strings into other text strings, with a minimal way of defining macros. This made the program more general and freed it from dependency on the syntax of the underlying language; I didn't have to write or maintain an HTML parser, and changes in the HTML spec would rarely require the tool to change. As in GPM and some RUNOFFs, I could set and evaluate string variables, and expand macros that accepted string variables as arguments.
I looked at the Unix m4 macro expander tool, written by friends of mine from Multics days. It wasn't available for the computer I had then. Perl was available on Unix, Windows, and Mac. I was already using it on Unix for report generation. Perl was very efficient and supported SQL and regular expressions.
Wherever possible, I used what was already available: I didn't invent a new file system, I used used my computer's OS file system; I didn't invent a text file format or editor, I used text files and tools provided on my computer; I didn't invent a file caching system, I depended on the server computer's file system caches; I didn't try to replace HTML, although I added a few abbreviation methods that expanded into HTML to avoid syntax errors. I didn't invent a database system, I used Perl's ability to interface with SQL, which I already knew.
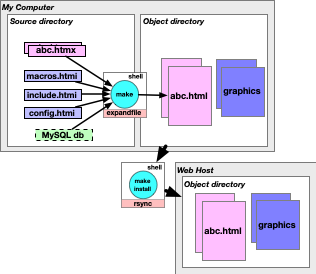
I studied the common errors I made when maintaining multicians.org, and chose or wrote tools that would prevent them. I implemented ways to store facts in an SQL database on my personal computer to ensure consistency among pages. Having each fact in one place was good only if I made sure to regenerate all object pages that used that fact: this led me to use the Unix make command. Another common error was forgetting to update every server file when I modified them on my computer: this led me to use the Unix rsync command, and rsync also provided compressed and encrypted transmission.
Using Expandfile to Generate Web Sites
I first used expandfile to translate "HTML with extensions" input (which I called HTMX) into HTML, mostly to include common boilerplate, such as page banners and CSS layout instructions used on all my web pages. I added features to allow source files to set variables that boilerplate files could use, like "page title" and "date updated" in the page header and footer. This saved typing, avoided errors, and made it easier to keep all pages consistent.
Builtin Functions
Adding builtin functions that could transform variables' values came next, then the ability to capture the output of shell commands run on my personal computer, and then integration with SQL data on my personal machine. I used these features to simplify my work flow for maintaining websites I created, and to eliminate special-purpose Perl programs in favor of logic in HTMX web page templates.
Wrappers
The big advance for me was introducing the *block builtin, and the pattern of writing HTMX files that
- Set parameter variables, and then defined a body block that included variable expansions.
- At the end of the source file, invoked the *include builtin function to expand a wrapper file that outputs headers, *expands the body block, and then outputs footers. (The header and footer can expand the parameter variables set by the main file, to set page titles and so on.)
- Obtained a consistent "look and feel" from files *included by the wrapper.
The wrapper pattern separates site boilerplate from page content, provides an independent source file for each HTML page, and makes it easy to regenerate a single page, or mny pages.
Using expandfile was also valuable when I made global changes to alter page layout, or to adapt to changing HTML specifications, or to improve support for mobile devices, or to use new browser features. Wrapper file changes were incorporated into every object page without having to edit all the source files.
I added the *shell builtin function to expandfile so that it could access operating system commands like date and invoke additional helper programs I wrote in Perl, like fmtnum and filedaysold.
Connecting expandfile to my local MySQL database and supporting *sqlloop was the next big step. This provided consistent formatting for lists of people, publications, glossary entries, and website page indexes, and defined a lightweight way for any HTMX file to refer to data from these lists. I used this to have multiple pages refer to facts that were kept in one place in SQL data. These changes reduced the chance that an editing mistake would screw up a whole page, or that I'd forget to update all the pages that used a fact.
Iterators
*sqlloop uses the iterator pattern that is invoked with an expression that produces a sequence of results, expands a block on each result, and accumulates the result. (In a way, this is just a generalization of "extract, transform, load" data processing I used to do in the 60s.) *sqlloop executes an SQL query that returns rows from the database, and temporarily binds each column name to a value. *sqlloop then expands an iterator block defined by *block to produce a string, expanding variables bound to row values. The string is concatenated onto the result of *sqlloop, and this pattern is repeated for each row returned by the query. (Notice that this is not type-safe: references in the iterator block have to match the names bound by the query.) *sqlloop is useful for formatting and presenting data in an SQL table. Similar constructs are also provided for CSV files: *csvloop, XML files: *xmlloop, and space-separated lists: *ssvloop.
Unix Tools
The third big step I took was using traditional Unix tools to invoked expandfile in order to automate site building and publishing. Using make (created years earlier for Unix by Multician Stu Feldman) to invoke expandfile only when an HTMX file was newer than its corresponding HTML file meant that I could make a one-line change to a file and then just type make install to recompile the minimum number of files and automatically rsync them to the deployment site.
Web Evolution
While I was addressing these issues of site generation, HTML and CSS standards and browser support for them kept evolving. expandfile helped me use the latest features, even as multicians.org grew in size.
Macros
There were times when I wanted to create repetitive formatting of a sequence of items, such as setting up picture galleries. I added the *callv builtin to expandfile to be able to easily execute a series of formatting steps, for example generating the HTML code to display a photo. (Each macro is defined as a *block, and arguments in the macro call are pushed and popped so that one macro can call another.) I made library files of macros that I can *include into a source file.
The macros for inserting IMG tags into a page output a warning if the image file cannot be found; if the file is found, the macros invoke a small helper program using *shell to get the pixel dimensions of the picture so they can be included in the IMG tag's WIDTH and LENGTH parameters. I don't have to look up every image's size and edit it into the source file, and specifying the sizes speeds up web browsers' loading of the HTML page.
Another example of macro use is the main expandfile page, whose source you can view at expandfile.htmx. That page has a section for each builtin function implemented by expandfile. The page defines a block called bif and begins each section with an invocation of bif as a macro, like *callv,bif,prototype,result,text. Using the macro ensures that each section heading is correctly formatted. The macro also formats a <tr> row for the summary table of all builtin functions, which is added to a text variable that will be inserted into a TABLE of functions using *include. The HTMX source that generates the main page is here.
Security
Several design choices I made were aimed at reducing the chance of attacks on my sites.
Early web sites were attacked from outsiders who found bugs in host operating systems and web servers. I decided that I wanted to use only the simplest features of a web server to transmit the contents of read-only files. This design also meant that each web page could be read-only, cached in the server memory, and served with quick response.
I chose not to require dynamic generation of pages, or to allow site visitors to cause any computation on the server. These choices limited some page designs: for example, I couldn't provide a "hit counter" on every page. I ruled out "Chat" and "comment" features: if site visitors couldn't upload any data, there would be less chance that attack code could get executed, and I didn't have to try to detect spam and inappropriate content.
Other Applications of Expandfile
As expandfile developed, I found other uses for it, including reformatting database files and preparing input for other programs such as input to procmail, RSS feed declarations in XML, shell scripts, input to the dot graphical compiler, and XML sitemap files for the Google crawler.
For some features, I use expandfile to expand a template which generates HTMX files which are in turn expanded by expandfile; this lets me do "two pass" expansions so I can add up totals and then display the values in headings above the detailed information.
In 2004, I wrote a web statistics application, Super Webtrax, which uses expandfile to produce a daily website usage report, with charts and tables generated from web server log data loaded into SQL.
For a document formatting application, I extracted data from data files in a proprietary format, translated it to SQL and loaded it into a local MySQL database, used expandfile's *sqlloop builtin to generate HTML, invoked a browser to format the HTML and export the formatted output to PostScript, and used page impression tools to generate a booklet.
I have also built template files that use the *shell builtin to fire off curl commands that fetch XML data from Web APIs, and then parse the returned data with *xmlloop to generate web service usage reports in HTML.
Language Issues
I originally wrote expandfile in Perl 5, and used it on Unix, macOS and Windows, through years of evolution of my program, the Perl language, and the features provided on different platforms. I showed expandfile to friends, but they were put off by the difficulty of installing and configuring the Perl implementation:
- Using CPAN library modules requires installing them. For example, expandfile uses Perl module DBD::mysql, which must be available even if a particular HTMX program does not use SQL. Similarly, expandfile requires XML::LibXML even if you don't use *xmlloop. Installing the Perl CPAN libraries required by expandfile may take hours of downloading, installing, and configuring.
- Installing CPAN modules sometimes requires that other utility programs be installed on the computer and configured first. For example, installing DBD::mysql fails unless MySQL is installed and configured.
- Different revision levels are provided on different platorms: e.g. macOS no longer provides and up-to-date Perl, so users have to install it.
I have occasionally looked for other languages to inplement expandfile in, such as Go and Rust. See expandfile-go.
Later Improvements
Early versions of expandfile had some features that I later decided were mistakes. Fortunately, nobody but me was using the program, and I knew where all the HTMX source files were. So I backed up the program and sources, created and tested a new program version, modified every source file that had to change, recompiled everything, compared old output to new, and accounted for changes before switching over to the new version.
Some of the changes were bug fixes or added new features, such as *xmlloop and *format. A few changes were made when Perl syntax changed and the program had to be updated.
I made the following changes in early 2021:
- Eliminated little-used syntax that gave special meaning to two characters: instead, implemented the functions as library macros for the few places that need it.
- Eliminated unnecessary control argument -config; configuration files are just expanded for side effect before other input files.
- Renamed implementation variables to prefix their names with _xf_ to avoid collisions with user variable names.
- Added configuration variable _xf_expand_multics to enable or disable Multics features; eliminated -mult control argument.
- Allowed multiple args to *shell, *fwrite, *fappend, and *htmlescape -- concatenate them with no separator.
- Added the *bindcsv function to replace a potentially exploitable practice.
- Made error messages more specific and added runtime checks for installation and implementation errors.
- Reimplemented, tested, and documented the configuration and install mechanisms.
- Created a comprehensive test suite.
- Updated documentation and added a Unix man page.
- Placed all expandfile source on GitHub with MIT Open Source license. "Share and enjoy."
In 2015, Google Webmaster Tools warned me that some of my site's pages were hard to read on mobile devices, and that this might penalize my site's search ranking. I made changes for mobile friendliness by modifying wrapper files and re-expanding all pages. The new wrappers set the VIEWPORT for most pages, and changed site navigation and menus to work better on small screens.
Comparison to other approaches
PHP
PHP programs are parsed and interpreted at runtime on every view; their execution can output HTML, access databases, and so on. Web servers can be configured to invoke the PHP interpreter when serving a file containing PHP constructs that look like <?php echo '<p>Hello World</p>'; ?> PHP can set and refer to variables that have string values. PHP has over 1000 builtin functions, including SQL access, and is very popular. I didn't choose PHP, because I wanted a tool that could be deployed without modifying the web server configuration. (PHP also has a long history of security bugs, and I thought they might scare users away from a tool that required it.)
Markdown
Markdown converts a simple text language into HTML. Some Web bulletin board systems allow users to type in their postings in Markdown, and translate the input to HTML. Markdown is often used as a way to collect user comments and input, and allow formatting of the input, without requiring users to learn HTML syntax. There are several different dialects of Markdown. It's easy to learn, but it doesn't support the features I needed for a full-featured web page.
Hugo
I learned a little about Hugo recently. Hugo is based on Markdown instead of Perl. It is implemented in the Go language and uses Go's conventions about modules and source organization. Similar to expandfile, Hugo input consists of HTML and extension constructs -- Hugo uses {{ ... }} instead of %[ ... ]% . It has variables, function expansion, and function definition. Looks slick. It supports multi-language translation, templates, themes, and static websites.